



Building Information Modeling (BIM) technology is now being implemented extensively by the Architecture, Engineering, Construction and Owner/Operator industry throughout the lifecycle of a facility—from the initial planning, design, construction, all the way through to operations—and for a large variety of processes—such as clash detection, 4D scheduling, 5D estimating, 6D sustainability, 7D facility management, and laser scanning. Various industry communities have developed standards for BIM, including construction operations building information exchange (COBie), industry foundation classes (IFC), and level of detail/development (LoD). Given the increasing use of BIM technology, it is extremely important to understand and explore the underlying BIM data.
The primary benefit of BIM is that it allows multiple disciplines to work together and collaborate on a single model. Using a single model poses challenges, particularly for very large projects; these challenges are generally related to hardware limitations, software interoperability, and model administration limitations. The solution is to use a work breakdown structure (WBS) strategy that uses several models and different databases, for example 4D, 5D, etc.
While using a WBS solution solves certain challenges, it involves the use of “big data,” which can lead to data discrepancies, among other challenges. Resolving big data discrepancies and maintaining the accuracy of BIM big data, standards, and requirements is time-consuming. AECOM has achieved significant time savings and improved accuracy by using data science for machine learning, data mining, statistics, and data visualization. Data science has many aspects, and innovative workflow changes can be made within it to optimize efficiencies depending on business needs and available databases. This article will focus on some of subfields of data science, workflow, and key issues related to BIM. Figure 1 shows the relationship of BIM, data warehouse, and data science, along with some of the subfields that contribute to data science.
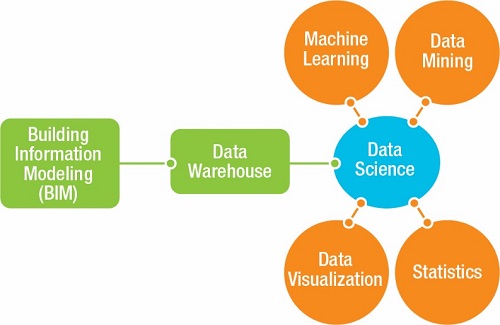
Data science involves extracting information from various data resources and formats (e.g., multidisciplinary BIM models, 4D, 5D, COBie, etc. in the context of BIM)—often referred to as the Extract Transform Load (ETL) process—to compile the data needed for solving real-world problems in a specific domain. The key in data science is to ask questions that the data can answer. Basically, there are five key questions that data science answers, as shown in Figure 2.

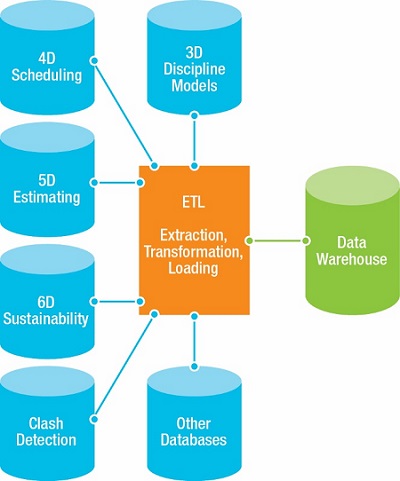
ETL is the process used to extract information from various resources and formats and transform that raw data into a uniform data structure, which is then suitable for data warehousing and data integration. Figure 3 shows examples of building-related information that can undergo the ETL process before being stored in a data warehouse. BIM databases usually contain three types of data: structured, semi-structured, and unstructured. Each of these needs to go through the ETL process, described below:
Extract: The initial part of the ETL process involves extracting valuable BIM data from a variety of data resources such as BIM models (e.g., model elements such as doors, levels, and spaces), Excel spreadsheets, HTML files, and flat files. In the extracting process, dark data (data that is not used for other purposes) may be needed.
Transform: The next process is transformation, which is one of the most important ETL processes involved in preparing proper data for the target data warehouse. In the transformation process, a range of functions is applied to the data. The functions include identifying the data types, cleaning the data, finding missing values, and designating desired columns. These functions are applied to the extracted data to ensure the quality of the data before it is loaded into the data warehouse and into the uniform data structure.
Load: The last step of the ETL process is to load the extracted and transformed data to a target data warehouse.
Machine learning is a subfield of data science (see Figure 1). Information that has undergone the ETL process and is stored in a data warehouse facilitates machine learning. Machine learning depends on a dataset and algorithms to predict answers to questions without explicit programming. As a simplified description, machine learning involves training datasets by using various kinds of machine learning algorithms.
For example, assume a user wants to predict whether information is true or false or missing in a BIM model as compared with the BIM standards, project standards, the BIM execution plan, or other BIM documents. Machine learning algorithms can be used to make predictions based on a given element feature (i.e., line weight, color, line pattern, etc.) as input data. Responses (output) may be true/false/ missing based on the algorithms applied to the BIM dataset. Output can also produce predictions to new data that is processed by ETL. A simple example to illustrate this concept would be email filtering algorithms that identify whether a given email is spam or not spam. The machine can be trained to continue the process until the desired level of accuracy is achieved.
Two commonly used kinds of machine learning algorithms are supervised learning algorithms and unsupervised algorithms. They are described below:
Supervised Learning Algorithms. Supervised learning algorithms are the most commonly used and significant for BIM because elements are categorized in the system and both input and output data can be trained easily so the system can generate accurate insights to resolve problems. The following are commonly used supervised learning algorithms:
Unsupervised Learning Algorithms. Unsupervised learning algorithms do not have category information. Additional element features (for example, element shape and size) must be added in order to categorize the elements. The purpose of unsupervised learning algorithms is to identify patterns in the data to categorize for output. The following are commonly used unsupervised learning algorithms:
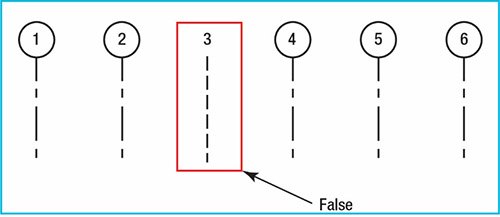
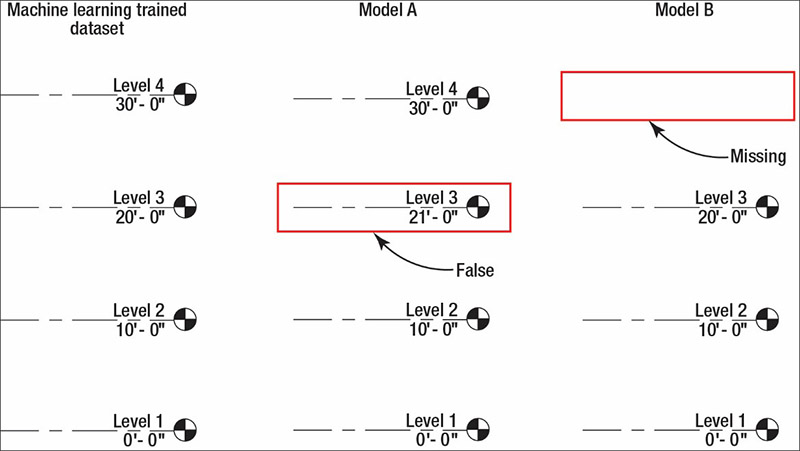
The following two examples illustrate possible problems in the BIM data. Figure 4 shows machine learning algorithms with one false output and five true outputs. Figure 5 shows a machine learning trained dataset and machine learning algorithms output, Model A and Model B. Model A has a false Level 3 because it is inconsistent with the trained dataset (left hand column) and the Model B output is missing Level 4.
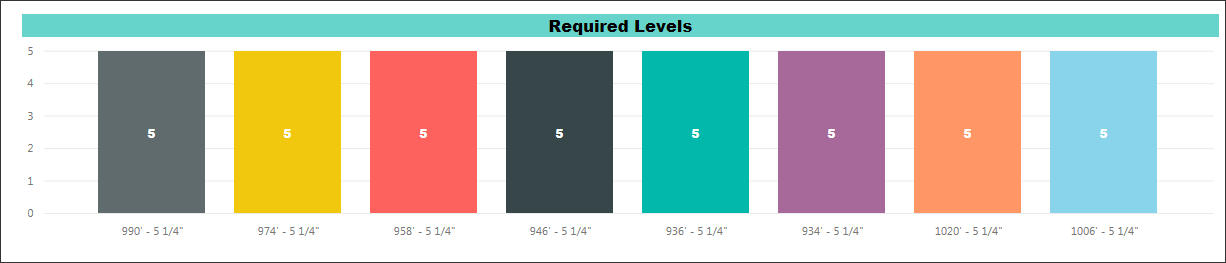
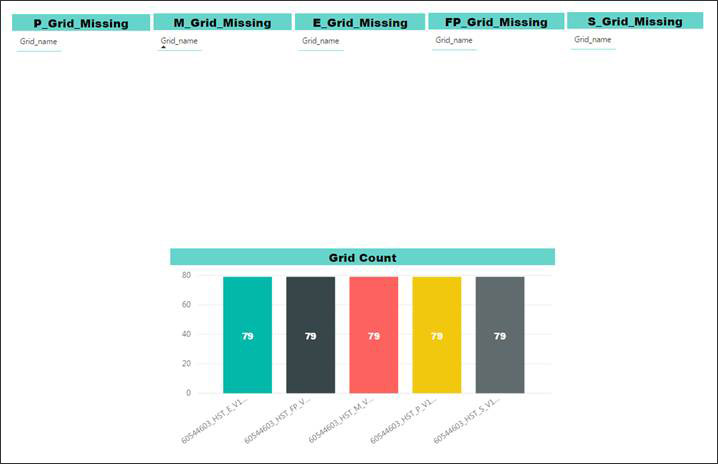
Machine learning output can be presented in graphic form to help users identify where the data is inconsistent or incomplete. For example, AECOM has internally developed a tool that executes the ETL process and machine learning algorithms to predict problems in the BIM data and provides reports and insights using the following visualization tools. Data visualization can be generated at several levels as needed to support a project team. It can be generated at the project level (Figure 6), model level (Figure 7), and element level (Figures 8 and 9). Providing visualization at these levels allow users to view the same information, but at different levels of detail.
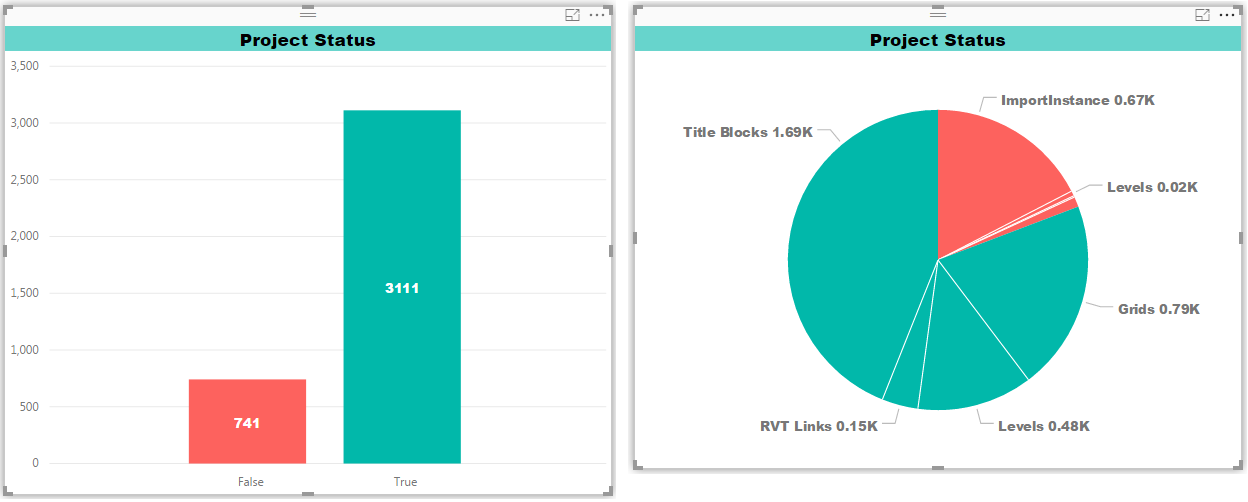
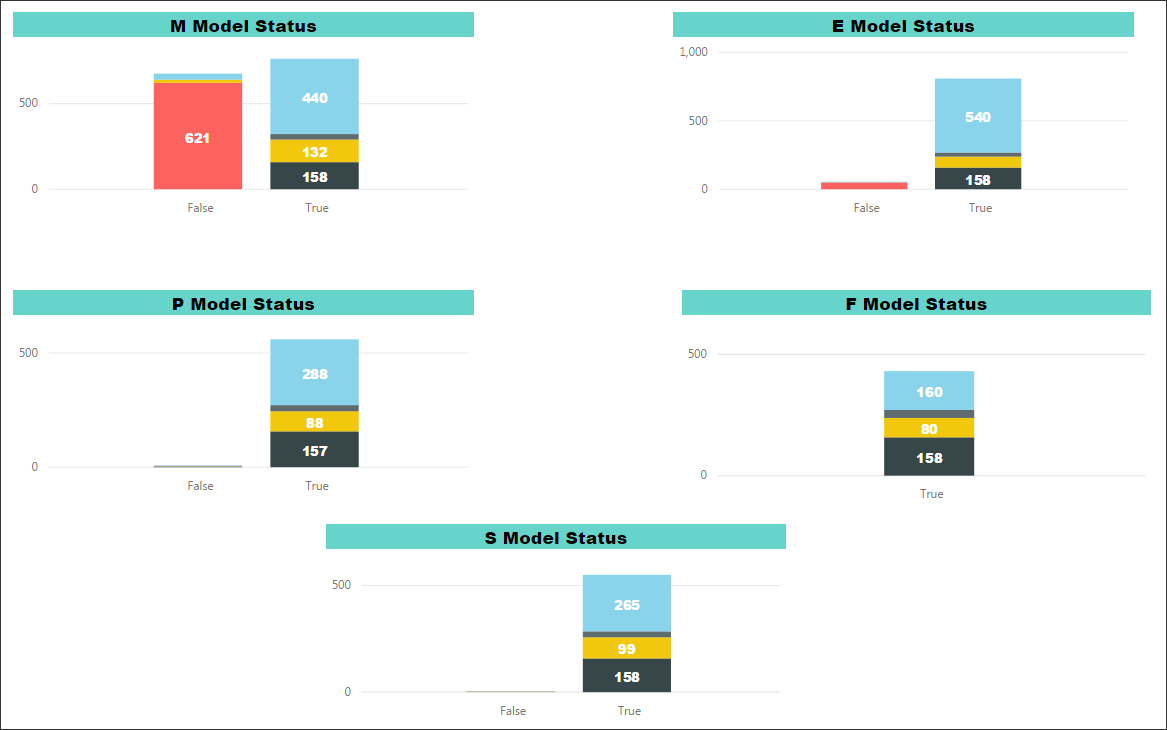
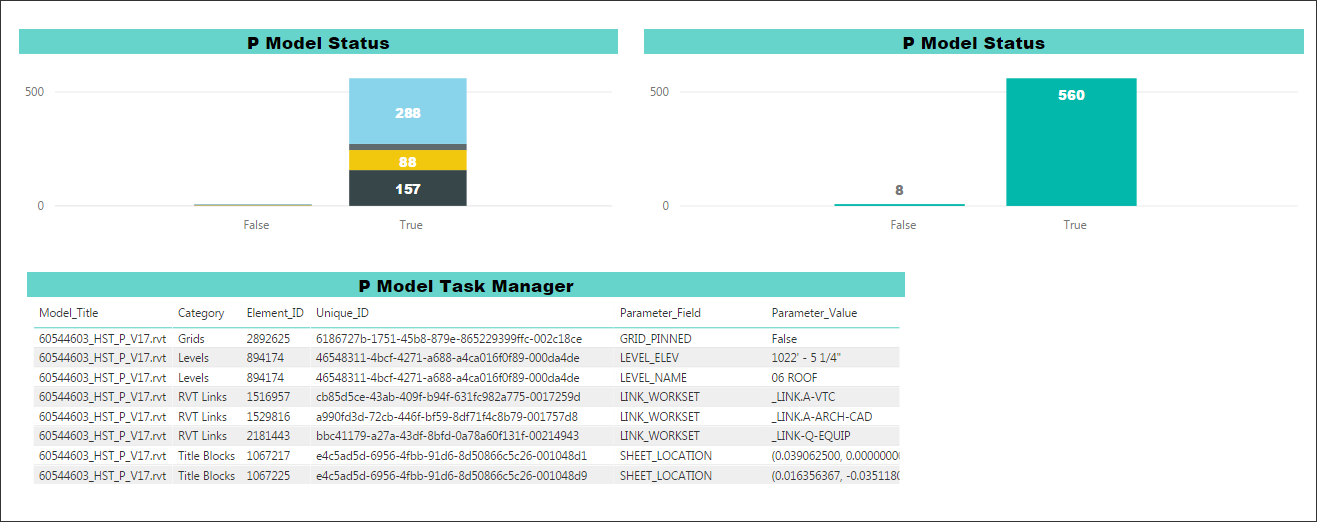
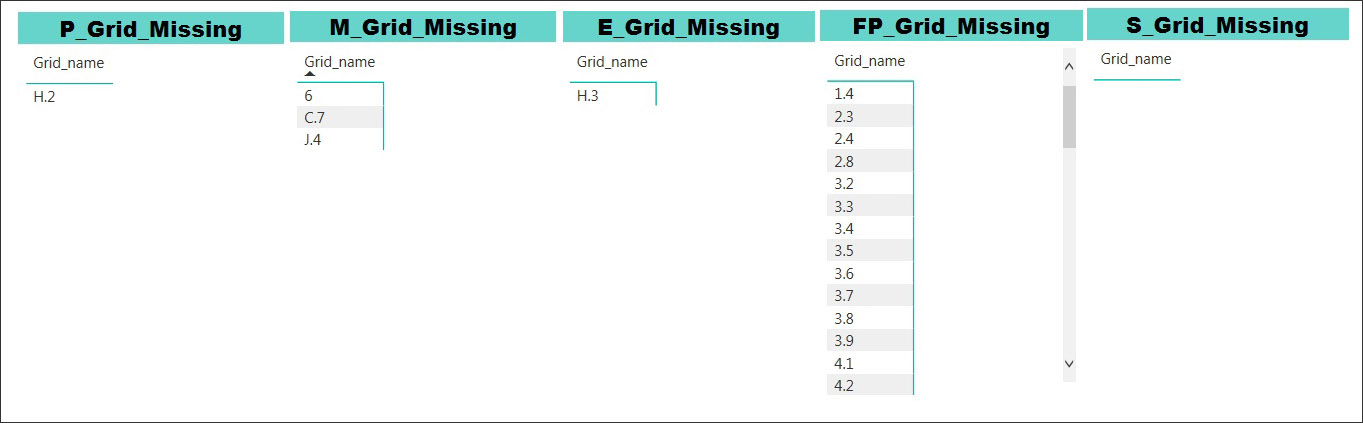
Figures 10 and 11 show visualizations that illustrate a successful outcome for data science using ETL and machine learning algorithms. These examples demonstrate accuracy of all the models.
The use of advanced machine learning algorithms can significantly reduce the amount of time required for identifying BIM data discrepancies by humans and for verifying information manually. Data science helps generate data visualizations and reports within minutes and makes it possible to share information over the cloud, which can be accessed from anywhere and on any secure device. Visualizations and reports can be generated on an hourly, daily, and weekly basis. The Architecture, Engineering, Construction and Owner/Operator industry has invested heavily in BIM technology and BIM standards, and has developed execution plans, policies, and procedures related to it. Using BIM data effectively is key to making better business decisions. The examples included in this article reflect the basic concepts that can be applied. The use of machine learning algorithms has only just begun: Our task is to explore the use of advanced algorithms to improve the use of BIM technology in AEC.
 Rashid Siddiqui is BIM Manager and Data Scientist at AECOM in the Roanoke, VA office. He has over 20 years of experience as a national BIM manager in the Architecture, Engineering, Construction and Owner/Operator industry. Mr. Siddiqui is credited with successfully pioneering the adoption of BIM technology and productively managing over 100 BIM projects, both nationally and internationally. He has directed, managed, and supported a variety of project types by using BIM technology including healthcare, religious, educational, hospitality, government, aviation, commercial, and mixed-use facilities valued between $20 million to $2.5 billion. He has developed BIM employer’s information requirements on several mega projects.
Rashid Siddiqui is BIM Manager and Data Scientist at AECOM in the Roanoke, VA office. He has over 20 years of experience as a national BIM manager in the Architecture, Engineering, Construction and Owner/Operator industry. Mr. Siddiqui is credited with successfully pioneering the adoption of BIM technology and productively managing over 100 BIM projects, both nationally and internationally. He has directed, managed, and supported a variety of project types by using BIM technology including healthcare, religious, educational, hospitality, government, aviation, commercial, and mixed-use facilities valued between $20 million to $2.5 billion. He has developed BIM employer’s information requirements on several mega projects.
Have comments or feedback on this article? Visit its AECbytes blog posting to share them with other readers or see what others have to say.
AECbytes content should not be reproduced on any other website, blog, print publication, or newsletter without permission.